

Capire la foresta casuale: Un metodo d'insieme
Il modello random forest (RF), proposto per la prima volta da Tin Kam Ho nel 1995, è una sottoclasse di metodi di apprendimento in ensemble che viene applicata alla classificazione e alla regressione. Un metodo ensemble costruisce un insieme di classificatori - un gruppo di alberi decisionali, nel caso di RF - e determina l'etichetta per ogni istanza di dati prendendo la media ponderata dei risultati di ciascun classificatore.
L'algoritmo di apprendimento utilizza l'approccio divide et impera e riduce la varianza intrinseca di una singola istanza del modello attraverso il bootstrapping. Pertanto, l'"assemblaggio" di un gruppo di classificatori più deboli aumenta le prestazioni e il classificatore aggregato risultante è un modello più forte.
La foresta decisionale casuale è una modifica del bagging - aggregazione bootstrap, proposta da Leo Breiman nel 2001 - che assembla una grande collezione di alberi decorrelati su caratteristiche selezionate casualmente[1]. Il ``numero di alberi`` che compongono la foresta è legato alla varianza del modello, mentre la ``profondità dell'albero`` o il ``numero massimo di nodi di cui ogni albero è composto`` è associato al bias irriducibile presente nel modello.

La RF presenta una serie di vantaggi: È molto veloce da implementare ed eseguire (funziona in modo efficiente su grandi insiemi di dati), è uno degli algoritmi di apprendimento più accurati e resistente all'overfitting e agli outlier[2]. Le prestazioni di RF sono simili, ma più robuste, di quelle degli alberi decisionali potenziati dal gradiente (GBDT), un'altra sottoclasse di metodi ad albero. Inoltre, poiché RF ha un numero inferiore di iperparametri rispetto a GBDT, è più facile da addestrare e mettere a punto. Di conseguenza, RF è molto popolare ed è supportato in vari linguaggi, come R e SAS, e in molti pacchetti in Python, tra cui scikit-learn e TensorFlow.
Stimatore TensorForest: Compatibilità e utilizzo
TensorFlow ha recentemente incluso il supporto per RF nella base di codice contribuita - tf.contrib - attraverso un modulo chiamato tensor_forest (definito in https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/tensor_forest/__init__.py, si noti che il link a tensor_forest sul sito ufficiale di TensorFlow indirizza l'utente al ramo con la versione più recente e non al ramo master). La versione 1.3.0 di tensor_forest è stata modificata in modo significativo rispetto alla versione 1.2.0 e la struttura del codice e i parametri da discutere sono conformi alla versione 1.2.0.
Struttura e implementazione di TensorForest
I seguenti moduli devono essere importati per utilizzare tensor_forest:
- from tensorflow.contrib.learn.python.learn import metric_spec
- from tensorflow.contrib.learn.python.learn.estimators import estimator
- from tensorflow.contrib.tensor_forest.client import eval_metrics
- from tensorflow.contrib.tensor_forest.client import random_forest
- from tensorflow.contrib.tensor_forest.python import tensor_forest
Il passo iniziale per eseguire RF in TensorFlow è la costruzione del modello. Per costruire uno stimatore RF, specificare innanzitutto gli iperparametri di RF come segue:
hparams = tensor_forest.ForestHParams(num_classes=NUM_CLASSES,num_features=NUM_FEATURES,num_trees=NUM_TREES,max_nodes=MAX_NODES,min_split_samples=MIN_NODE_SIZE).fill()Ciascuno degli iperparametri per la foresta tensoriale sopra menzionati è descritto di seguito:
``num_classes``: Il numero di classi possibili per le etichette
``num_features``: Il numero di caratteristiche. Sia ``num_splits_to_consider`` che ``num_features`` dovrebbero
Secondo i collaboratori del codice di tensor_forest, il modello è più accurato.
quando ``num_splits_to_consider`` == ``num_features``[4].
``num_trees``: Il numero di alberi da costruire per prendere la modalità [per la classificazione] o la media [per
regressione] delle previsioni. Gli alberi sono "notoriamente rumorosi", quindi "traggono grande beneficio dalla media"[5]. Più alberi compongono la foresta, più bassa è la varianza del modello e quindi più accurati sono i risultati. Tuttavia, esiste un compromesso tra prestazioni e velocità di esecuzione. L'utilizzo di un numero elevato di alberi comporta un maggiore costo computazionale e potrebbe rallentare significativamente il codice. Di solito, dopo un certo numero di alberi, le prestazioni del modello si stabilizzano e il miglioramento è trascurabile[6].
Mi piace costruire una foresta a cinque alberi per testare il mio codice a scopo di debug, una a 100 alberi per avere un'idea iniziale di accuratezza, precisione, richiamo, auc, ecc. e una a 500 alberi per un modello finale che non necessita di grandi aggiustamenti. In generale, l'uso di un modello a 1000 alberi non aumenta significativamente le prestazioni rispetto a una foresta a 500 alberi.
*Default: 100
I due iperparametri seguenti determinano la profondità dell'albero in una foresta. Limitare la profondità dell'albero non dà alcun vantaggio aggiuntivo, se non quello di limitare il tempo di calcolo, e non è raccomandato[7]. Maggiore profondità significa minore polarizzazione. Quando gli alberi "crescono sufficientemente in profondità, [hanno] un bias relativamente basso"[8].
``max_nodes``: Il numero massimo di nodi consentito per ogni albero. Un numero maggiore di ``max_nodes``
permette di avere alberi più profondi.
*Valore predefinito: 10000.
``min_split_samples``: "Il numero minimo di campioni richiesti per dividere un nodo interno" secondo
SKlearn[9]. ``min_split_samples'' è legato alla dimensione minima dei nodi. Minore è il numero di campioni necessari per dividere un nodo, maggiore è la profondità dell'albero.
*Default: 5

Quindi, determinare il tipo di grafo da utilizzare con RF; esistono due tipi di grafi: Il grafo RF predefinito [``RandomForestGraphs``] e il grafo delle perdite di addestramento [``TrainingLossForest``][11]. Per quanto riguarda l'antecedente, l'utente può aumentare il peso delle istanze positive, di solito per insiemi di dati sbilanciati, passando un vettore di pesi.
[Nota: ``SKCompat`` è il wrapper di scikit-learn per TensorFlow[12]. ``model_dir`` deve essere una directory in cui vengono salvati il RF e il file di log per la visualizzazione con tensorboard].
Se è selezionato il grafico RF:
Per specificare un sovrappeso:
graph_builder_class = tensor_forest.RandomForestGraphs
est = estimator.SKCompat(random_forest.TensorForestEstimator(
params,
graph_builder_class=graph_builder_class,
model_dir=MODEL_DIRECTORY,
nome_pesi='pesi'))
Oppure mantenere la ponderazione predefinita di 1:1 tra i punti di dati positivi e negativi:
graph_builder_class = tensor_forest.RandomForestGraphs
est = estimator.SKCompat(random_forest.TensorForestEstimator(
params,
graph_builder_class=graph_builder_class,
model_dir=MODEL_DIRECTORY))
Nel caso della foresta di perdita di addestramento, la perdita di addestramento calcolata dalla funzione di perdita predefinita [``log_loss``] o da una funzione di perdita specificata viene utilizzata per regolare i pesi[13].
Usa la funzione di perdita predefinita ``log loss`` come funzione di perdita:
classe_di_costruttore_di_grafo = tensor_forest.TrainingLossForest
Oppure specificare una funzione di perdita da utilizzare nel grafico delle perdite di addestramento[14]:
da tensorflow.contrib.losses.python.losses import loss_ops
# Le funzioni di perdita valide sono:
#["absolute_difference",
#"add_loss",
#"coseno_distanza",
#"compute_weighted_loss",
#"get_losses",
#"get_regularization_losses",
#"get_total_loss",
#"hinge_loss",
#"log_loss",
#"mean_pairwise_squared_error",
#"mean_squared_error",
#"sigmoid_cross_entropy",
#"softmax_cross_entropy",
#"sparse_softmax_cross_entropy"]
def loss_fn(val, pred):
_loss = loss_ops.hinge_lss(val, pred)
restituire _loss
def _build_graph(params, **kwargs):
return tensor_forest.TrainingLossForest(params,
loss_fn=_loss_fn, **kwargs)
graph_builder_class = _build_graph
Infine, costruire lo stimatore RF con gli iperparametri e il grafico specificati in precedenza. est= estimator.SKCompat(random_forest.TensorForestEstimator(
hparams,
graph_builder_class=graph_builder_class,
model_dir=MODEL_DIRECTORY))
Dopo aver costruito il RF, è necessario adattare il modello ai dati di allenamento con il metodo ``fit``.
Per il grafico RF con peso massimo specificato*:
est.fit(x={‘x’:x_train, ‘weights’:train_weights},
y={‘y’:y_train},
batch_size=BATCH_SIZE,
max_steps=MAX_STEPS)
*Nota: `pesi` deve essere la stessa chiave passata in ``TensorForestEstimator`` in precedenza.
``train_weights`` dovrebbe essere dimensione: (numero di campioni, )
Per la ponderazione predefinita 1:1 o la foresta di perdita di formazione:
est.fit(x=x_train, y=y_train
batch_size=BATCH_SIZE,
max_steps=MAX_STEPS)
Per valutare i risultati prodotti dal modello, occorre identificare le metriche desiderate e passarle alla funzione ``evaluate``[15].
# Altre metriche includono:
# veri positivi: tf.contrib.metrics.streaming_true_positives
# veri negativi: tf.contrib.metrics.streaming_true_negatives
# falsi positivi: tf.contrib.metrics.streaming_false_positives
# falsi negativi: tf.contrib.metrics.streaming_false_negatives
# auc: tf.contrib.metrics.streaming_auc
# r2: eval_metrics.get_metric('r2')
# precisione: eval_metrics.get_metric('precision')
# richiamo: eval_metrics.get_metric('recall')
metric = {‘accuracy’:metric_spec.MetricSpec(eval_metris.get_metric(‘accuracy’),
prediction_key=eval_metrics.get_prediction_key('accuracy')}
Se viene somministrato il sovrappeso:
model_stats = est.score(x={‘x’:x_test, ‘weights’:test_weights},
y={‘y’:y_test},
batch_size=BATCH_SIZE,
max_steps=MAX_STEPS,
metriche=metriche)
per metrica in model_stats:
print('%s: %s' % (metrica, model_stats[metrica])
Per la ponderazione predefinita e la foresta di perdita di formazione:
model_stats = est.score(x=x_test, y=y_test
batch_size=BATCH_SIZE,
max_steps=MAX_STEPS,
metriche=metriche)
per metrica in model_stats:
print('%s: %0.4f' % (metrica, model_stats[metrica])
Per l'etichetta prevista e la probabilità di ogni classe per ogni istanza di dati:
[Nota: ``predicted_prob`` e ``predicted_class`` sono array numpy che conservano l'ordine dell'input originale].
Peso massimo specificato:
predictions = dict(est.predict({‘x’:x_test, ‘weights’:test_weights}))
predicted_prob = predictions[eval_metrics.INFERENCE_PROB_NAME]
predicted_class = predictions[eval_metrics.INFERENCE_PRED_NAME]
Ponderazione predefinita e foresta di perdita di formazione:
previsioni = dict(est.predict(x=x_test))
predicted_prob = predictions[eval_metrics.INFERENCE_PROB_NAME]
predicted_class = predictions[eval_metrics.INFERENCE_PRED_NAME]
Infine, avviare tensorboard tramite il terminale per visualizzare il processo di addestramento e il grafico TensorFlow:
Deve essere fornita la directory precedentemente passata a ``model_dir``.
$ tensorboard --logdir="./"
Aprire http://localhost:6006/ o il link ottenuto eseguendo il comando precedente nel browser per visualizzare tensorboard.

Confronto tra TensorFlow e Scikit-Learn per i modelli di foresta casuale
Attualmente, TensorFlow e scikit-learn sono entrambi pacchetti molto popolari, ciascuno con team di esperti che contribuiscono e mantengono la base di codice, una miriade di tutorial sull'uso del codice online e in stampa, la copertura della maggior parte degli algoritmi di apprendimento automatico. Tuttavia, questi due moduli non sono destinati agli stessi compiti.
scikit-learn

Scikit è da tempo considerato il "framework ufficiale di apprendimento automatico generale di Python"[17]. Offre una base di codice completa di algoritmi di apprendimento automatico che appartengono a varie categorie: classificazione, regressione, clustering, riduzione della dimensionalità, ecc[18]. Questi algoritmi ben confezionati forniscono agli utenti un accesso immediato a un'analisi facile e veloce del set di dati. Ad esempio, sklearn include un modulo RF che può essere implementato su set di dati con poche righe:

Oltre alla sua semplicità d'uso e alle API standardizzate, scikit-learn è anche straordinariamente ben documentato. Per ogni libreria, ci sono pagine dedicate non solo ai dettagli dell'interfaccia, ai parametri di ingresso e al formato di uscita, ma anche alla dimostrazione dell'uso del codice con esempi accuratamente costruiti. Utilizziamo ancora una volta il modulo RF di sklearn come illustrazione specifica:
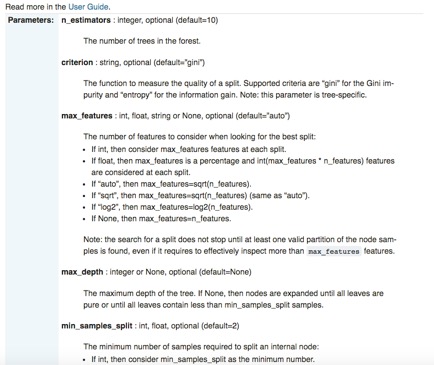

Sebbene scikit-learn presenti numerosi vantaggi di rilievo, come la "brevità sintattica"[22], ha una particolare lacuna: sklearn non supporta e non supporterà le GPU nel prossimo futuro[23]. "Il supporto delle GPU introdurrà molte dipendenze software e problemi specifici della piattaforma. [...] Al di fuori delle reti neurali, le GPU non svolgono oggi un ruolo importante nell'apprendimento automatico", secondo il sito ufficiale di sklearn. D'altra parte, il supporto nativo di TensorFlow per le GPU lo rende particolarmente adatto al deep learning.
TensorFlow
La potenza di TensorFlow è data dalla sua scalabilità che permette di "addestrare reti neurali profonde su GPU[ e] possibilmente su cluster di più macchine"[24] e dalla libertà concessa agli utenti nell'assemblare i propri algoritmi di deep learning. Gli utenti specificano non solo il tipo di modello utilizzato, ma anche il modo in cui viene implementato utilizzando le primitive fornite dal framework[25]. Essi definiscono esattamente "come [...] i dati devono essere trasformati [e] quale funzione di perdita deve ottimizzare il modello"[26]. Inoltre, TensorFlow è altamente flessibile e portatile; è disponibile su numerose piattaforme - tra cui Ubuntu, Mac OS X, Windows, Android, iOS - e su una varietà di linguaggi, come Python, Java, C, Go[27]. Sebbene sembri particolarmente attraente per la sua scalabilità e integrabilità, la complicata struttura del codice di TensorFlow, i misteriosi messaggi di errore e, in alcuni casi, i moduli scarsamente documentati appesantiscono il processo di debug. Pertanto, l'utilizzo di TensorFlow per "la maggior parte delle attività pratiche di apprendimento automatico" è probabilmente eccessivo[28].
Introduzione a Scikit Flow: collegamento tra TensorFlow e Scikit-Learn
[https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/learn/python/learn]
Scikit flow (SKFlow) è stato introdotto come soluzione al dilemma scikit-TensorFlow: sfrutta la "potenza di modellazione di TensorFlow incanalando la brevità sintattica di scikit-learn"[29]. SKFlow è un progetto ufficiale sviluppato da Google che fornisce un wrapper semplificato di alto livello per TensorFlow[30].
Una rete neurale a tre strati con 10, 20 e 10 unità nascoste rispettivamente può essere implementata con quattro linee in SKFlow:

Oppure costruire un modello personalizzato con SKFlow con circa 10 righe di codice:
