

AGGIORNAMENTO: questo post è stato aggiornato per riflettere le nuove informazioni apprese in collaborazione con i team AWS S3 Replication, CloudTrail e Security.
Una strategia di backup completa è fondamentale per qualsiasi piano di DR. Ma come distinguere tra attività di backup legittime e sottrazione di dati dannosa?
Gli autori degli attacchi informatici stanno acquisendo sempre più spesso l'accesso ai pianicloud , che includono funzionalità per eseguire backup cloud. In questo articolo mostrerò come questi strumenti possono essere sfruttati per sottrarre dati dall'ambiente di produzione di un'organizzazione.
In questo blog vedrete da vicino come un hacker può sfruttare la replica S3 per migrare in modo efficiente i vostri dati fuori dal vostro ambiente. Spero che lo troviate interessante da leggere quanto lo è stato da creare.
Vedrete questo attacco svolgersi in archi narrativi separati dal punto di vista dei quattro diversi attori elencati qui.
- Il servizio di replica S3, poiché segue in modo innocuo gli ordini dettati come regole di replica per replicare i dati S3 tra i bucket.
- Il servizio di replica Evil S3, poiché i suoi poteri vengono abusati per copiare dati in posizioni esterne.
- L'autore dell'attacco che ottiene il controllo del servizio di replica S3, cooptandolo per scopi malevoli e sfruttando la sua mancanza di registrazione per rimanere sotto il radar.
- I membri del team SOC (centri operativi di sicurezza) che scoprono di essere parzialmente all'oscuro dei movimenti dei dati tramite il servizio di replica S3, ma che ora possono modificare la loro strategia di rilevamento per compensare tale lacuna.
Presentazione del servizio di replica S3, delle sue funzionalità e dei casi d'uso più interessanti
Il servizio AWS S3 non è più il "Simple Storage Service" che era stato concepito. Con decine di funzionalità e integrazioni, è diventato l'archivio dati preferito dai clienti AWS aziendali. È anche così complicato che è difficile comprenderne e quindi garantire tutte le sue funzionalità. Una delle numerose funzionalità di S3 è la capacità di copiare i dati tra regioni e account, creando backup attivi dei dati.
Come puoi vedere in questo post, questa funzione è soggetta ad abusi e può essere difficile da monitorare.

Il servizio di replica in AWS fa esattamente quello che ci si aspetterebbe: quando viene impostato con delle regole, copia i dati S3 tra i bucket.
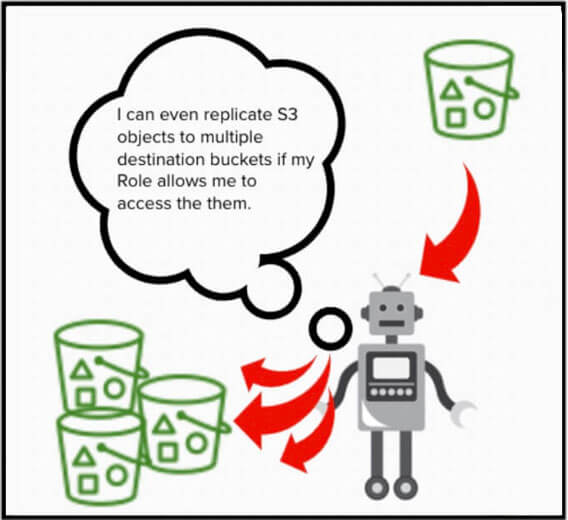
Il servizio riceve gli ordini dalle regole di replica. È possibile configurare le regole per indicare al servizio di copiare i dati in più bucket, creando più repliche dello stesso oggetto di origine.
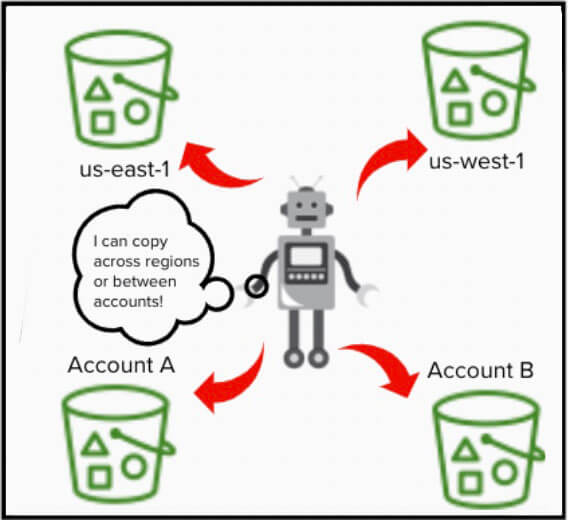
I bucket di destinazione non devono necessariamente trovarsi nella stessa regione o nello stesso account del bucket di origine.
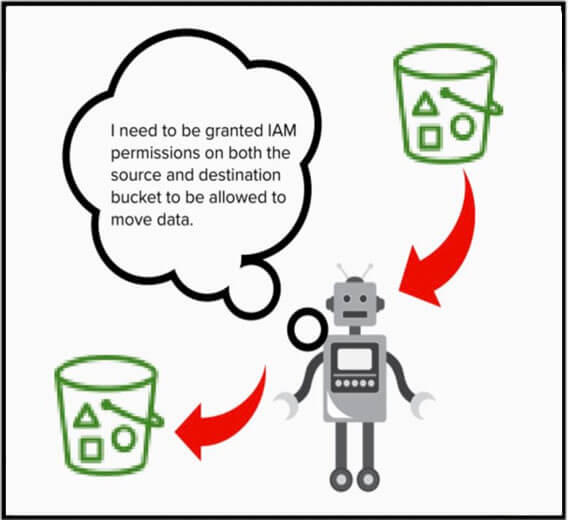
Le sue funzionalità di replica dei dati sono disponibili solo se al servizio vengono concesse le autorizzazioni necessarie. Per abilitare il servizio di replica S3, è necessario configurarlo in modo che assuma un ruolo IAM a cui vengono concesse le autorizzazioni IAM per accedere sia al bucket di origine che a quello di destinazione.
Quali sono le conseguenze se un hacker riesce a usare la replica S3 in AWS?

La replica tra account può aiutare le organizzazioni a riprendersi da un evento di perdita di dati. Tuttavia, se utilizzato in modo improprio, il servizio di replica consente agli autori delle minacce di sottrarre dati e trasferirli in luoghi non sicuri.

Il servizio di replica S3 presenta un elevato potenziale di abuso e, di conseguenza, è uno dei principali obiettivi degli hacker.

Se un malintenzionato riuscisse a ottenere la possibilità di creare regole di replica, potrebbe ordinare al servizio di replica S3 di copiare i dati in un bucket esterno controllato da lui stesso. Anche uno che risiede al di fuori dell'organizzazione AWS della vittima.
Quali autorizzazioni IAM sono necessarie per la replica esterna?
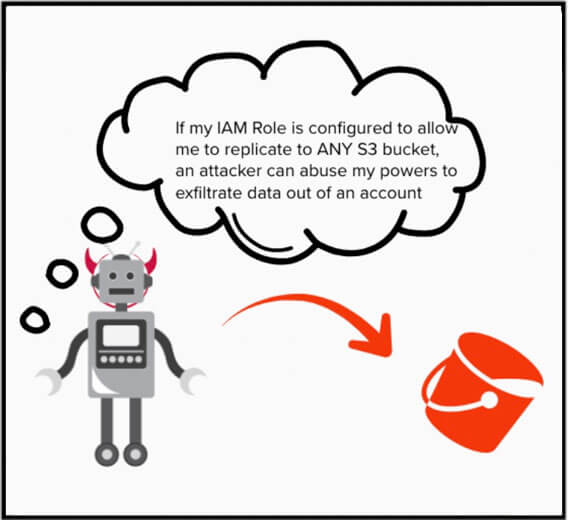
Il servizio di replica S3 richiede autorizzazioni sugli oggetti S3 sia per ottenere l'oggetto dal bucket di origine sia per replicarlo nel bucket esterno controllato dall'autore dell'attacco.
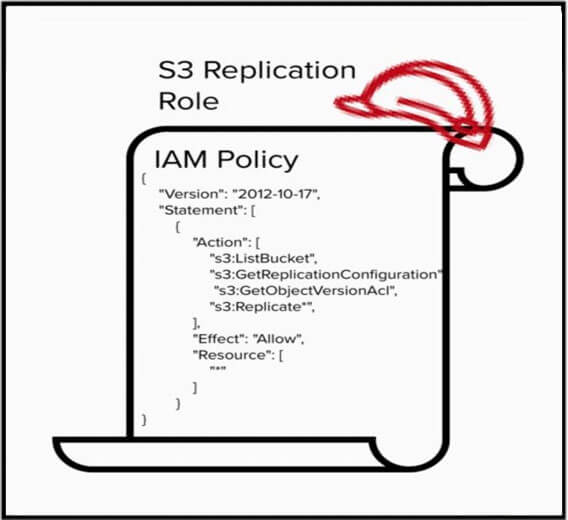
Ecco un esempio di politica IAM che definisce le azioni necessarie per la replica, ma trascura di limitare le autorizzazioni a una risorsa, lasciando il campo della risorsa come "*". Questa politica è così permissiva che consentirebbe al servizio di replica S3 di copiare oggetti in qualsiasi bucket, anche quelli esterni al proprio account.

Data una politica eccessivamente permissiva, un aggressore dovrebbe avere la possibilità di aggiornare le regole di replica, indicando al servizio di replica di copiare i dati in un bucket controllato dall'aggressore. Non sono necessarie autorizzazioni sugli oggetti stessi, ma solo la possibilità di aggiornare le regole.
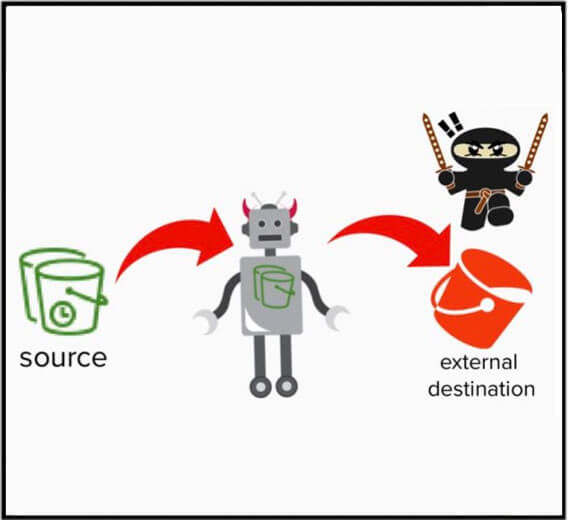
Ricapitolando: invece di copiare o spostare direttamente i dati da un account, il servizio di replica S3 può essere sfruttato da un malintenzionato per eseguire le stesse azioni per proprio conto, come risultato di una regola di replica dannosa. Non si tratta di un bug che può essere risolto, ma piuttosto di un tipo di cloud chiamata "abuso di funzionalità".
In che modo il servizio di replica S3 registra le proprie attività? E in che modo ciò aiuta un aggressore a passare inosservato?
Il trasferimento autorizzato dei dati tramite il servizio di replica S3 è poco trasparente, rendendo particolarmente difficile individuare l'esfiltrazione dei dati e consentendo agli hacker di nascondere le loro attività all'interno cloud vostro cloud .

Vediamo quando e dove il servizio di replica scrive gli eventi su CloudTrail in base alle configurazioni del percorso del piano dati e all'ambito del bucket.
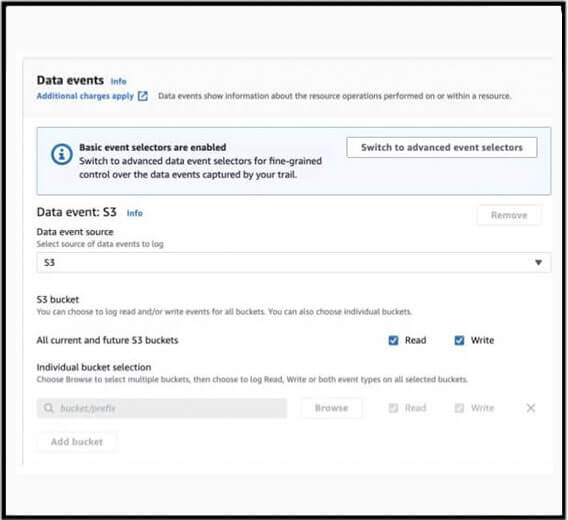
Per ottenere visibilità sugli eventi che interessano gli oggetti S3, è necessario attivare la raccolta degli eventi relativi ai dati S3. L'ambito di questi eventi può essere configurato in modo da includere "Tutti i bucket S3 attuali e futuri" oppure è possibile enumerare singoli bucket. Questa impostazione di CloudTrail funge da meccanismo di filtraggio per includere bucket specifici nella registrazione del piano dati S3.
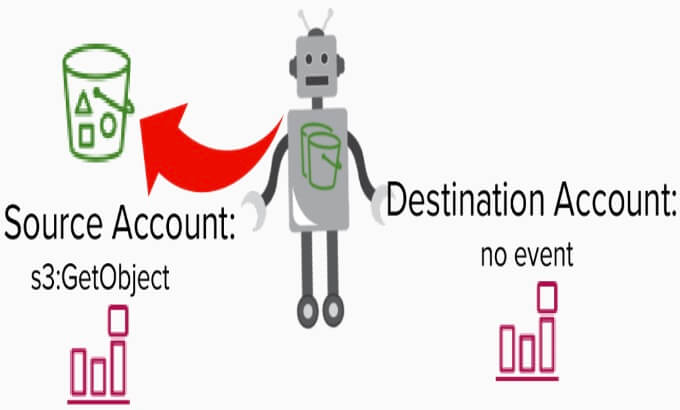
Quando i dati vengono copiati dal servizio di replica S3, viene generato un evento GetObject poiché il servizio acquisisce l'oggetto durante la replica. Questo evento viene registrato nel CloudTrail dell'account di origine.
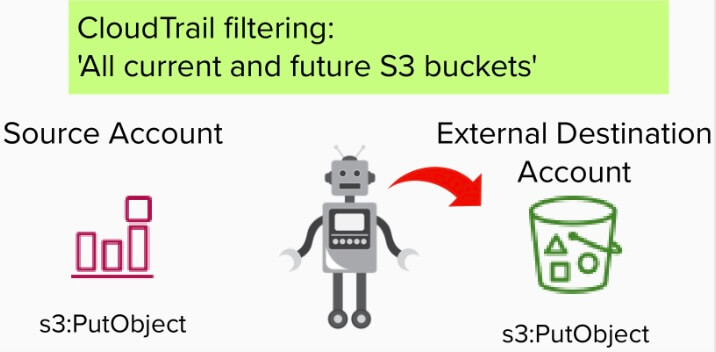
Dopo l'evento GetObject, l'evento PutObject, che rivela il bucket di destinazione, viene registrato sia nell'account di destinazione esterno che nell'account di origine.
Qual è il comportamento della registrazione del piano dati CloudTrail S3 se i log sono limitati a bucket specifici?
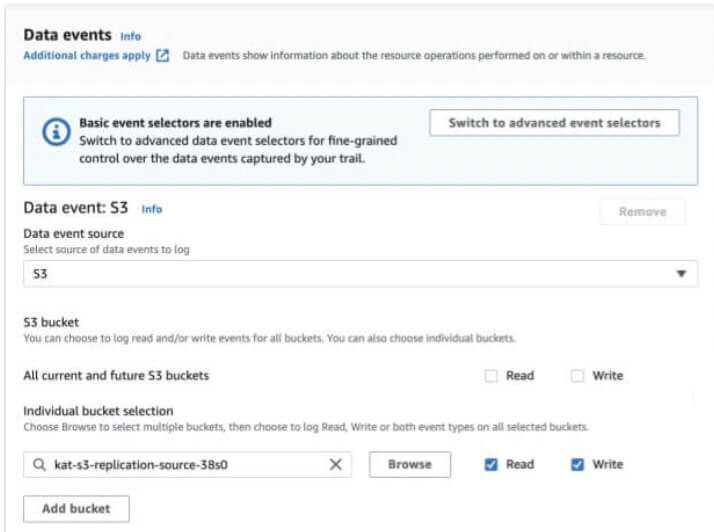
Per controllare i costi, le organizzazioni spesso abilitano i log del piano dati S3 solo sui bucket di alto valore, anziché pagare per la registrazione su "tutti i bucket attuali e futuri". In che modo questa configurazione di registrazione modifica la visibilità del servizio di replica S3?
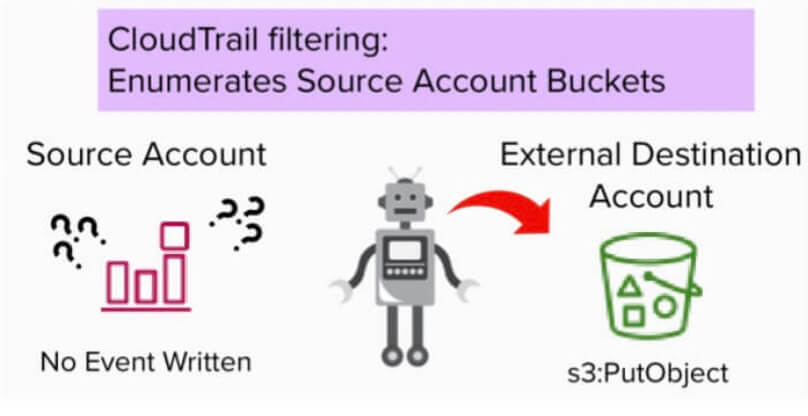
A seguito dell'evento GetObject , un evento PutObject potrebbe essere registrato nell'account di destinazione in base alla configurazione CloudTrail dell'account di destinazione. In particolare, nessun evento PutObject verrà registrato nell'account di origine.

In pratica, ciò significa che, poiché i dati vengono copiati dal servizio di replica, nel CloudTrail dell'account di origine non è presente alcun record che riveli il bucket di destinazione esterno.

Quando CloudTrail è configurato per acquisire eventi del piano dati S3 da bucket specifici dell'account di origine, esiste una lacuna nella registrazione che consente la copia dei dati senza registrare l'evento del piano dati, PutObject, nell'account di origine.
Senza registri dei data plane che includano i registri di tutti i bucket attuali e futuri, un malintenzionato potrebbe aggiornare le regole di replica per replicare gli oggetti nel proprio bucket esterno, quindi sedersi e rilassarsi mentre il servizio di replica sposta silenziosamente i dati fuori dall'organizzazione.
Fortunatamente, i controlli preventivi sono chiari.
Come sempre, quando si definiscono le politiche di identità AWS IAM, non lasciare vuoto il campo delle risorse consentendo alle autorizzazioni della politica di applicarsi a qualsiasi politica. Assicurarsi che il ruolo IAM assunto dal servizio di replica elenchi esplicitamente i bucket su cui è consentito operare.
Quali sono le conseguenze per cloud ?
I cacciatori di minacce possono utilizzare l'aggiornamento dannoso delle regole di replica come indizio del fatto che nel loro ambiente potrebbe verificarsi silenziosamente un'esfiltrazione di dati.

Considerando quanto sia prevenibile l'abuso dei servizi con S3 Replication Service, perché questa mancanza di visibilità è importante per i cacciatori di minacce e cloud di tutto il mondo?

Per capire perché queste incongruenze nella registrazione sono importanti, dobbiamo discutere della missione dei difensori all'interno di un'organizzazione. Cloud pongono continuamente domande cloud alla ricerca di indicatori di compromissione. Il loro compito è quello di rilevare quando le cose vanno storte, nonostante i migliori sforzi delle misure preventive.

Il pane quotidiano di un difensore sono i log che utilizza per creare rilevamenti che forniscono segnali di allarme precoci quando i dati si spostano dal perimetro. I log del piano dati a disposizione dei difensori possono essere limitati solo a bucket noti e di alto valore per affrontare le questioni relative ai costi e ridurre l'enorme volume di log del piano dati che può essere generato quando si acquisiscono tutti i dati.

Se i dati possono essere copiati senza che venga registrato il bucket di destinazione, i difensori non possono segnalare in modo completo o cercare l'esfiltrazione dei dati cercando bucket danneggiati in eventi del piano dati come CopyObject o PutObject.

I difensori devono ampliare gli eventi che monitorano per includere l'aggiornamento delle regole di replica, in modo da garantire un monitoraggio completo del proprio perimetro di dati.
Se un SOC non è in grado di applicare la registrazione del piano dati S3 su "tutti i bucket attuali e futuri", il monitoraggio e l'avviso sull'evento PutBucketReplication è l'unico modo in cui un difensore avrà visibilità sui bucket di destinazione esterni. Questo evento non indica che i dati sono stati copiati, ma solo che il servizio di replica ha una regola configurata per copiare i dati.

Lezioni apprese dall'uso improprio del servizio di replica
Il servizio di replica S3 può essere utilizzato per aiutare le organizzazioni a diventare più resilienti al ransomware, ma è importante, quando si costruisce il nostro modello di minaccia, creare scenari malevoli che ci aiutino a vedere cloud dal punto di vista di un aggressore.
A causa dei costi, un'organizzazione tipica potrebbe essere riluttante ad abilitare la registrazione del piano dati S3 su tutti i bucket di un account, preferendo acquisire in modo selettivo solo i log dei bucket di alto valore. Come abbiamo visto, tale strategia comporterà una lacuna nella visibilità dell'esfiltrazione S3, poiché l'evento PutObject non verrà scritto nell'account di origine.
Ad agosto 2022, AWS aveva rifiutato di risolvere il problema di registrazione con il servizio di replica S3. Nel corso delle discussioni con AWS, sono state proposte le seguenti soluzioni o "richieste di funzionalità".
- Includere il bucket di destinazione nell'evento GetObject
- Preferibilmente, considera gli eventi GetObject e PutObject come coppie, scrivendo questi due eventi nell'account di origine come risultato del filtro di ambito del bucket di origine, piuttosto che considerare l'ambito del log del piano dati del bucket di destinazione.
Tempistica di segnalazione
21
[Vectra]: Segnalazione iniziale della vulnerabilità inviata e ricevuta confermata lo stesso giorno.
21
[AWS]: Ha risposto indicando che non ritiene che si tratti di una vulnerabilità:
"Non riteniamo che il comportamento descritto in questo rapporto rappresenti un problema di sicurezza, ma piuttosto un comportamento previsto. Offriamo CloudWatch alarming che registrerà qualsiasi modifica apportata alla politica di replica di un bucket [1], fornendo visibilità sulla destinazione dei dati per il modello di minaccia descritto. Consultare la sezione che descrive in dettaglio "S3BucketChangesAlarm".
21
[Vectra]: Richiesta conferma che AWS non considera la mancanza di registrazione una vulnerabilità. Indicazione che descriverò la risposta di AWS a questa segnalazione come "non risolvibile" in qualsiasi comunicazione pubblica.
21
[AWS]: AWS mi ha chiesto dove avrei pubblicato la divulgazione e se potevano avere una copia anticipata del testo.
21
[Vectra]: Ha confermato che potrebbe ricevere una copia anticipata di qualsiasi comunicazione pubblica.
22
[Vectra]: Ha inviato nuovamente il rapporto originale sulla vulnerabilità a un contatto interno del team di sicurezza AWS, suggerendo di presentare una richiesta per migliorare la registrazione sul servizio di replica S3.
22
[AWS]: Confermato che hanno inserito il ticket internamente.
22
[Vectra]: Pubblicata una ricerca iniziale sull'argomento che descriveva il problema di registrazione come verificatosi solo quando era abilitato il controllo del tempo di replica (RTC).
22
[Vectra]: Nuovi test effettuati per individuare una mancanza di registrazione con o senza RTC abilitato.
26/7/22
[Vectra]: Presentazione dei risultati al fwd:cloudSec
22
[Vectra e AWS]: incontro per discutere i risultati. Durante questo incontro è stato chiarito che il filtro di ambito del piano dati CloudTrail S3 è il meccanismo che controlla se un evento PutObject viene scritto o meno nell'account di origine.
[1] https://docs.aws.amazon.com/awscloudtrail/latest/userguide/awscloudtrail-ug.pdf