

Definire l'intelligenza artificiale (IA) è un compito complesso, spesso soggetto a prospettive in continua evoluzione. Le definizioni basate su obiettivi o compiti possono cambiare con il progresso della tecnologia. Ad esempio, i sistemi di gioco degli scacchi erano al centro delle prime ricerche sull'IA fino a quando Deep Blue di IBM sconfisse il grande maestro Gary Kasparov nel 1997, cambiando la percezione degli scacchi da gioco che richiedeva intelligenza a gioco che richiedeva tecniche di forza bruta.
D'altra parte, le definizioni di IA che tendono a concentrarsi su aspetti procedurali o strutturali spesso si impantanano in questioni filosofiche fondamentalmente irrisolvibili riguardanti la mente, l'emergenza e la coscienza. Queste definizioni non aiutano a comprendere meglio come costruire sistemi intelligenti né a descrivere i sistemi che abbiamo già realizzato.
Il test di Turing: una misura dell'intelligenza artificiale

Il test di Turing, spesso considerato un test di intelligenza artificiale, era il modo in cui Alan Turing eludeva la questione dell'intelligenza. Esso metteva in evidenza la vaghezza semantica dell'intelligenza e si concentrava su ciò che le macchine sono in grado di fare piuttosto che su come le etichettiamo.
"La domanda originale 'Le macchine possono pensare?' credo sia troppo insignificante per meritare una discussione. Tuttavia, credo che alla fine del secolo l'uso delle parole e l'opinione generale dei colti saranno cambiati così tanto che si potrà parlare di macchine pensanti senza aspettarsi di essere contraddetti."- Alan Turing
Alla fine, è una questione di convenzione, non molto diversa dal discutere se dovremmo riferirci ai sottomarini come "nuotanti" o agli aerei come "volanti". Per Turing, ciò che contava davvero erano i limiti di ciò che le macchine sono in grado di fare, non come ci riferiamo a tali capacità.
Misurare il pensiero umano nell'intelligenza artificiale
A tal fine, se volete sapere se le macchine possono pensare come gli esseri umani, la soluzione migliore è misurare quanto la macchina riesca a ingannare le altre persone facendogli credere che pensa come un essere umano. Seguendo Turing e la definizione fornita dagli organizzatori del primo workshop sull'intelligenza artificiale nel 1956, riteniamo analogamente che "ogni aspetto dell'apprendimento o qualsiasi altra caratteristica dell'intelligenza possa in linea di principio essere descritto con tale precisione da poter essere simulato da una macchina".
Per ottenere prestazioni o comportamenti simili a quelli umani in qualsiasi attività, l'IA dovrebbe essere in grado di simularli con un livello di precisione notevole. Il famoso test di Turing è stato progettato per valutare questa capacità, valutando l'efficacia con cui un computer o una macchina potesse ingannare un osservatore attraverso una conversazione non strutturata. Il test originale di Turing richiedeva addirittura che la macchina rappresentasse in modo convincente un'identità femminile.
Valutare la comprensione a livello umano dell'intelligenza artificiale
Negli ultimi anni, i significativi progressi nelle tecniche di apprendimento automatico, insieme all'abbondanza di dati di addestramento estesi, hanno consentito agli algoritmi di intrattenere conversazioni con una comprensione minima. Inoltre, tattiche apparentemente insignificanti, come l'inserimento deliberato di errori ortografici e grammaticali casuali, contribuiscono a rendere gli algoritmi sempre più persuasivi come esseri umani virtuali, nonostante la mancanza di intelligenza autentica.
Nuovi approcci alla valutazione della comprensione a livello umano, come gli schemi di Winograd, propongono di interrogare una macchina sulle sue conoscenze del mondo, sull'uso degli oggetti e sulle loro potenzialità, comunemente comprese dagli esseri umani. Ad esempio, se ponessimo la domanda: "Perché il trofeo non entrava nello scaffale? Perché era troppo grande. Cosa era troppo grande?", chiunque capirebbe immediatamente che il trofeo era l'elemento troppo grande. Al contrario, con una semplice sostituzione - "Il trofeo non entrava sullo scaffale perché era troppo piccolo. Cosa era troppo piccolo?" - chiediamo informazioni sull'inadeguatezza delle dimensioni.
In questo scenario, la risposta è inequivocabilmente nello scaffale. Questo test, con una precisione maggiore, approfondisce le conoscenze della macchina relative al mondo. Il semplice data mining da solo non può fornire una risposta. Questa definizione richiede che un'IA abbia la capacità di emulare qualsiasi aspetto del comportamento umano, tracciando una distinzione significativa dai sistemi di IA progettati specificamente per dimostrare intelligenza per compiti particolari.
Tipi di IA e relativi metodi di apprendimento
Intelligenza artificiale generale (AGI)
L'intelligenza artificiale generale (AGI), comunemente nota come IA generale, è il concetto più frequentemente discusso quando si parla di IA. Comprende i sistemi che evocano nozioni futuristiche di "robot dominatori" che governano il mondo, catturando la nostra immaginazione collettiva attraverso la letteratura e il cinema.
IA specifica o applicata
La maggior parte della ricerca in questo campo si concentra su sistemi di IA specifici o applicati. Questi comprendono una vasta gamma di applicazioni, dai sistemi di riconoscimento vocale e visione artificiale di Google e Facebook all'IA per la sicurezza informatica sviluppata dal nostro team di Vectra AI.
I sistemi applicati sfruttano in genere una vasta gamma di algoritmi. La maggior parte degli algoritmi è progettata per apprendere ed evolversi nel tempo, ottimizzando le proprie prestazioni man mano che acquisiscono accesso a nuovi dati. La capacità di adattarsi e apprendere in risposta a nuovi input definisce il campo dell'apprendimento automatico. Tuttavia, è importante notare che non tutti i sistemi di IA richiedono questa capacità. Alcuni sistemi di IA possono funzionare utilizzando algoritmi che non si basano sull'apprendimento, come la strategia di Deep Blue per giocare a scacchi.
Tuttavia, questi casi sono tipicamente limitati ad ambienti e spazi problematici ben definiti. Infatti, i sistemi esperti, un pilastro dell'IA classica (GOFAI), si basano fortemente su conoscenze preprogrammate e basate su regole invece che sull'apprendimento. Si ritiene che l'AGI, insieme alla maggior parte dei compiti di IA comunemente applicati, richieda una qualche forma di apprendimento automatico.

Il ruolo dell'Machine Learning
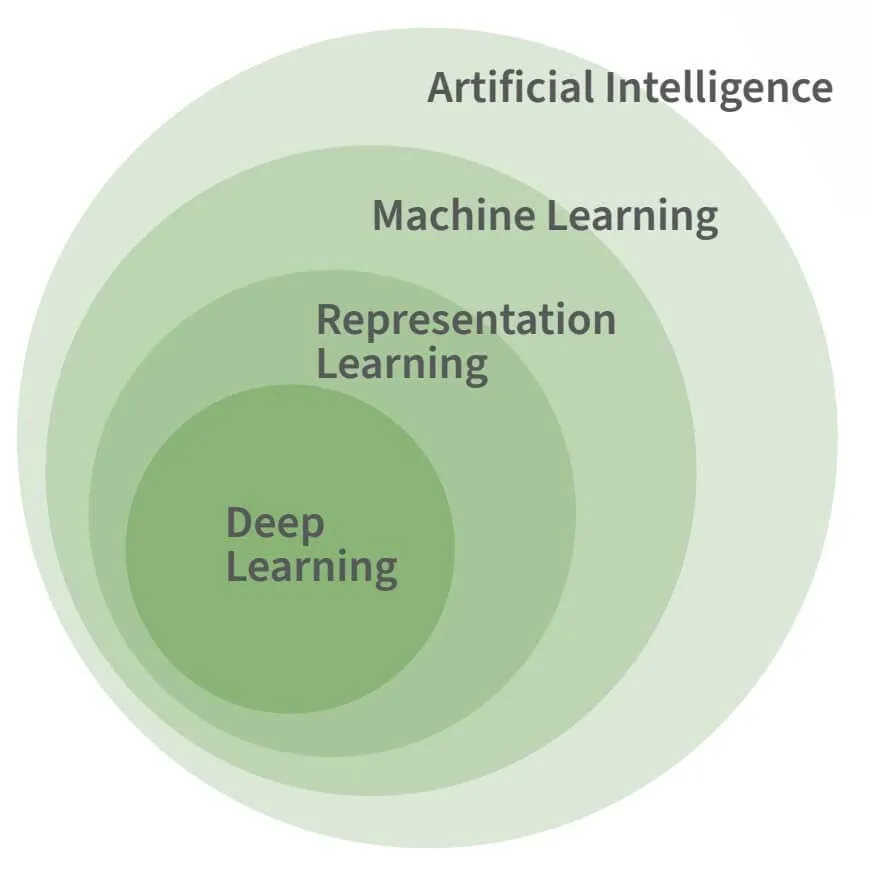
La figura sopra mostra la relazione tra IA, apprendimento automatico e apprendimento profondo. L'apprendimento profondo è una forma specifica di apprendimento automatico e, sebbene l'apprendimento automatico sia considerato necessario per la maggior parte delle attività avanzate di IA, non è di per sé una caratteristica necessaria o distintiva dell'IA.
L'apprendimento automatico è necessario per imitare gli aspetti fondamentali dell'intelligenza umana, piuttosto che le sue complessità. Prendiamo ad esempio il programma di intelligenza artificiale Logic Theorist sviluppato da Allen Newell e Herbert Simon nel 1955. Esso riuscì a dimostrare 38 dei 52 teoremi iniziali contenuti in Principia Mathematica, il tutto senza alcun bisogno di apprendimento.
AI, Machine Learning e Deep Learning: qual è la differenza?
L'intelligenza artificiale (AI), l'apprendimento automatico (ML) e l'apprendimento profondo (DL) vengono spesso erroneamente considerati come concetti identici, ma ciascuno di essi ha un significato specifico. Comprendendo il significato di questi termini, è possibile acquisire una visione approfondita degli strumenti che sfruttano l'intelligenza artificiale.
Intelligenza artificiale (AI)
L'intelligenza artificiale è un termine generico che comprende sistemi in grado di automatizzare il ragionamento e avvicinarsi alla mente umana. Ciò include sottodiscipline come ML, RL e DL. L'intelligenza artificiale può riferirsi a sistemi che seguono regole esplicitamente programmate così come a quelli che acquisiscono autonomamente comprensione dai dati. Quest'ultima forma, che apprende dai dati, è alla base di tecnologie come le auto a guida autonoma e gli assistenti virtuali.
Machine Learning ML)
Il ML è una sottodisciplina dell'IA in cui le azioni del sistema vengono apprese dai dati anziché essere esplicitamente dettate dagli esseri umani. Questi sistemi sono in grado di elaborare enormi quantità di dati per imparare a rappresentare e rispondere in modo ottimale a nuovi casi di dati.
Video: Machine Learning per i professionisti della sicurezza informatica
Representation Learning RL)
L'RL, spesso trascurato, è fondamentale per molte tecnologie di IA oggi in uso. Consiste nell'apprendimento di rappresentazioni astratte dai dati. Ad esempio, trasformare le immagini in elenchi di numeri di lunghezza costante che catturano l'essenza delle immagini originali. Questa astrazione consente ai sistemi a valle di elaborare meglio nuovi tipi di dati.
Deep Learning DL)
Il DL si basa sul ML e sul RL scoprendo gerarchie di astrazioni che rappresentano gli input in modo più complesso. Ispirati al cervello umano, i modelli DL utilizzano strati di neuroni con pesi sinaptici adattabili. Gli strati più profondi della rete apprendono nuove rappresentazioni astratte, che semplificano compiti come la categorizzazione delle immagini e la traduzione dei testi. È importante notare che, sebbene il DL sia efficace per risolvere determinati problemi complessi, non è una soluzione universale per l'automazione dell'intelligenza.
Riferimento: "Deep Learning", Goodfellow, Bengio & Courville (2016)
Tecniche di apprendimento nell'IA
Molto più difficile è il compito di creare programmi in grado di riconoscere il parlato o individuare oggetti nelle immagini, nonostante sia relativamente facile per gli esseri umani. Questa difficoltà deriva dal fatto che, sebbene sia intuitivamente semplice per gli esseri umani, non siamo in grado di descrivere una serie di regole semplici che consentano di individuare fonemi, lettere e parole dai dati acustici. È lo stesso motivo per cui non riusciamo a definire facilmente l'insieme di caratteristiche dei pixel che distinguono un volto da un altro.

La figura a destra, tratta dall'articolo di Oliver Selfridge del 1955, Pattern Recognition and Modern Computers (Riconoscimento dei modelli e computer moderni), mostra che gli stessi input possono portare a output diversi, a seconda del contesto. In basso, la H in THE e la A in CAT sono insiemi di pixel identici, ma la loro interpretazione come H o A dipende dalle lettere circostanti piuttosto che dalle lettere stesse.
Per questo motivo, si sono ottenuti risultati migliori quando alle macchine è stato permesso di imparare come risolvere i problemi piuttosto che cercare di predefinire quale fosse la soluzione.
Gli algoritmi ML hanno la capacità di ordinare i dati in diverse categorie. I due principali tipi di apprendimento, supervisionato e non supervisionato, svolgono un ruolo importante in questa capacità.
Apprendimento supervisionato
L'apprendimento supervisionato insegna a un modello con dati etichettati, consentendogli di prevedere le etichette per i nuovi dati. Ad esempio, un modello esposto a immagini di gatti e cani può classificare nuove immagini. Nonostante necessiti di dati di addestramento etichettati, etichetta efficacemente i nuovi punti dati.

Apprendimento non supervisionato
D'altra parte, l'apprendimento non supervisionato funziona con dati non etichettati. Questi modelli apprendono i modelli all'interno dei dati e possono determinare dove i nuovi dati si inseriscono in tali modelli. L'apprendimento non supervisionato non richiede una formazione preliminare ed è ottimo per identificare le anomalie, ma ha difficoltà ad assegnare loro delle etichette.
Entrambi gli approcci offrono una gamma di algoritmi di apprendimento, in continua espansione man mano che i ricercatori ne sviluppano di nuovi. Gli algoritmi possono anche essere combinati per creare sistemi più complessi. Sapere quale algoritmo utilizzare per un problema specifico è una sfida per i data scientist. Esiste un algoritmo superiore in grado di risolvere qualsiasi problema?

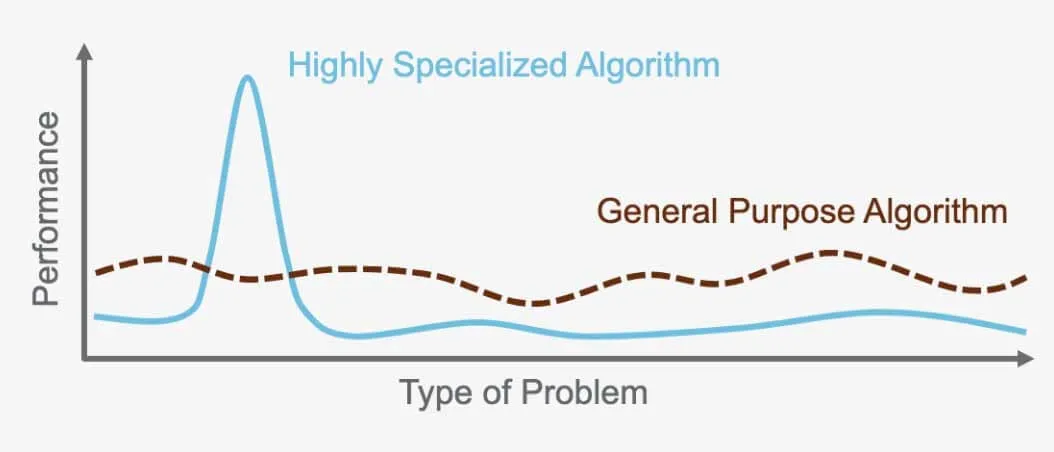
Il "No Free Lunch : non esiste un algoritmo universale
Il "No Free Lunch " afferma cheNo Free Lunch esiste un algoritmo perfetto in grado di superare tutti gli altri per ogni problema. Al contrario, ogni problema richiede un algoritmo specializzato e su misura per le sue esigenze specifiche. Ecco perché esistono così tanti algoritmi diversi. Ad esempio, una rete neurale supervisionata è ideale per determinati problemi, mentre il clustering gerarchico non supervisionato funziona meglio per altri. È importante scegliere l'algoritmo giusto per il compito da svolgere, poiché ciascuno di essi è progettato per ottimizzare le prestazioni in base al problema e ai dati utilizzati.
Ad esempio, l'algoritmo utilizzato per il riconoscimento delle immagini nelle auto a guida autonoma non può essere utilizzato per tradurre tra lingue diverse. Ogni algoritmo ha uno scopo specifico ed è ottimizzato per il problema che è stato creato per risolvere e per i dati su cui opera.
Selezionare l'algoritmo giusto nella scienza dei dati
Scegliere l'algoritmo giusto come data scientist è un mix di arte e scienza. Considerando la descrizione del problema e comprendendo a fondo i dati, il data scientist può essere guidato nella giusta direzione. È fondamentale riconoscere che fare la scelta sbagliata può portare non solo a risultati subottimali, ma anche completamente inaccurati. Dai un'occhiata all'esempio qui sotto:
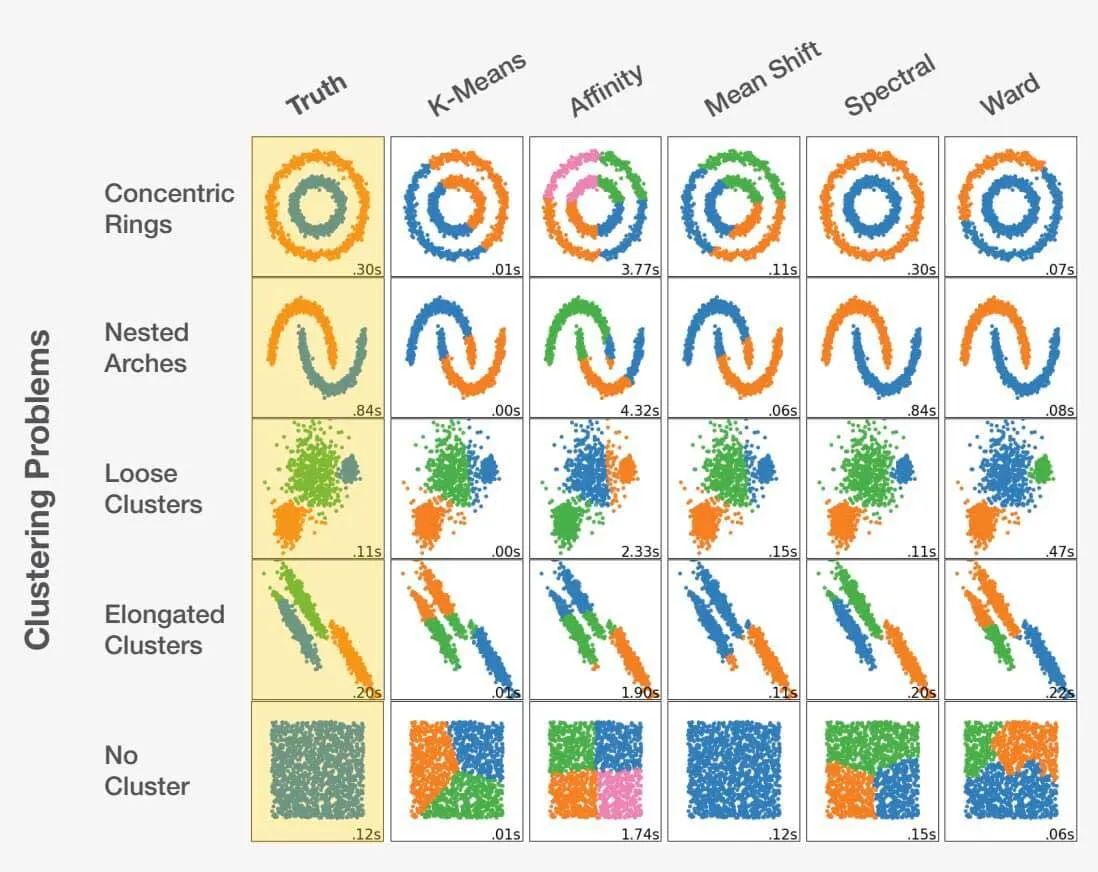
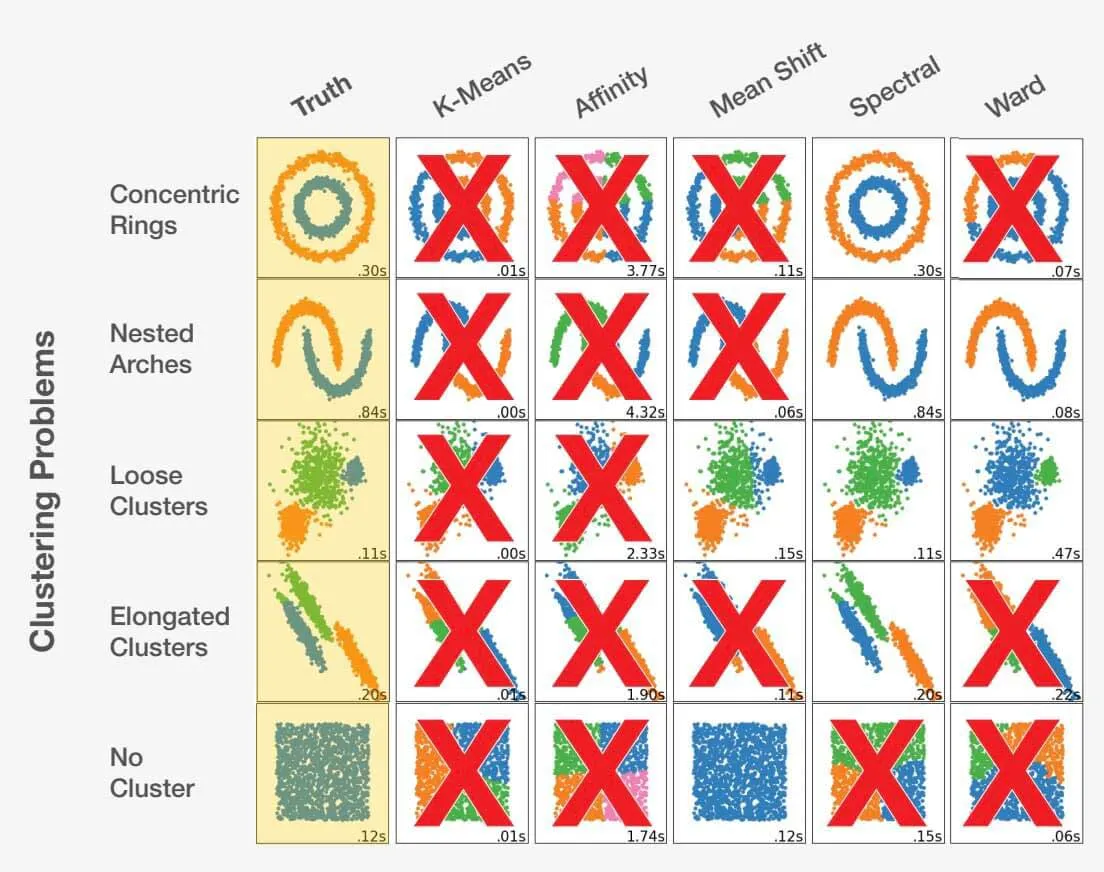
Adattato da scikit-learn.org.
La scelta dell'algoritmo giusto per un set di dati può influire in modo significativo sui risultati ottenuti. Ogni problema ha una scelta algoritmica ottimale, ma, cosa ancora più importante, alcune scelte possono portare a risultati sfavorevoli. Ciò evidenzia l'importanza fondamentale di selezionare l'approccio appropriato per ogni problema specifico.
Come misurare il successo di un algoritmo?
La scelta del modello giusto come data scientist non riguarda solo l'accuratezza. Sebbene l'accuratezza sia importante, a volte può nascondere le reali prestazioni di un modello.

Consideriamo un problema di classificazione con due etichette, A e B. Se l'etichetta A è molto più probabile dell'etichetta B, un modello può raggiungere un'elevata accuratezza scegliendo sempre l'etichetta A. Tuttavia, ciò significa che non identificherà mai correttamente nulla come etichetta B. Quindi l'accuratezza da sola non è sufficiente se vogliamo trovare i casi B. Fortunatamente, i data scientist dispongono di altre metriche per ottimizzare e misurare l'efficacia di un modello.
Una di queste metriche è la precisione, che misura quanto un modello sia corretto nell'individuare una determinata etichetta rispetto al numero totale di ipotesi. I data scientist che mirano a un'elevata precisione creeranno modelli che evitano di generare falsi allarmi.

Ma la precisione ci dice solo una parte della storia. Non rivela se il modello non riesce a identificare casi che sono importanti per noi. È qui che entra in gioco il richiamo. Recall la frequenza con cui un modello trova correttamente una particolare etichetta rispetto a tutte le istanze di quell'etichetta. I data scientist che mirano a un richiamo elevato costruiranno modelli che non tralasceranno istanze importanti.

Monitorando e bilanciando sia la precisione che il richiamo, i data scientist possono misurare e ottimizzare efficacemente i propri modelli per ottenere il successo.