

Hai presente quel momento in cui qualcuno dice: "Colleghiamo ChatGPT al SOC" e tutti annuiscono come se fosse perfettamente normale? Ebbene, questo post parla proprio di ciò che accade dopo quel momento.
Perché, per quanto possa sembrare interessante, aggiungere GenAI a un SOC non è una magia. È complicato. Richiede molti dati. E se non si misura ciò che sta realmente accadendo dietro le quinte, si rischia di automatizzare la confusione.
Quindi... abbiamo deciso di misurarlo.
GenAI nel SOC: un'idea interessante, una realtà difficile
Partiamo dall'ovvio: al momento l'intelligenza artificiale è ovunque nel settore della sicurezza.
Ogni presentazione SOC contiene una grande bolla denominata "GenAI Assistant". Tuttavia, la vera prova consiste nel verificare le prestazioni effettive di tali assistenti quando si trovano ad affrontare flussi di lavoro SOC reali.
Entra nel Vectra MCP Server, il controllore del traffico aereo per tutti i tuoi agenti AI.
Collega il tuo LLM (ad esempio ChatGPT o Claude) ai tuoi strumenti di sicurezza (e ai loro dati!), in questo caso Vectra AI.
L'MCP coordina arricchimento, correlazione, contenimento e contesto, consentendo al tuo agente AI di interagire direttamente con i segnali rilevanti invece di perdersi nei dashboard.
E poiché desideriamo che tutti possano sfruttare e sperimentare queste funzionalità, abbiamo rilasciato 2 server MCP che consentono di collegare qualsiasi piattaforma Vectra ai propri flussi di lavoro AI.
- ☁️ RUX — il nostro SaaS: http://github.com/vectra-ai-research/vectra-ai-mcp-server
- 🖥️ QUX — la nostra versione on-premise: http://github.com/vectra-ai-research/vectra-ai-mcp-server-qux
Quindi, se avete pensato: "Vorrei poter collegare il mio LLM al mio stack di sicurezza e vedere cosa succede", ora potete farlo. Nessuna licenza complicata, nessun accordo di riservatezza, basta collegarlo e iniziare a utilizzarlo.
Noi di Vectra AI crediamo sinceramente che GenAI + MCP cambieranno radicalmente il modo in cui operano i SOC.
Non si tratta di un'idea per il futuro: è già realtà e stiamo facendo in modo che Vectra AI siano pienamente attrezzati per sfruttare questo cambiamento.
Questo è anche il motivo per cui dedichiamo molto tempo a dialogare con clienti, potenziali clienti e partner: per comprendere la rapidità con cui queste tecnologie stanno evolvendo e cosa significa realmente essere "pronti per l'LLM" in un SOC attivo.
Quindi... abbiamo deciso di misurarlo.
Perché se GenAI sta per rivoluzionare le operazioni di sicurezza, allora dobbiamo essere assolutamente certi che la nostra piattaforma, i nostri dati e le nostre integrazioni MCP possano inserirsi perfettamente in questo nuovo mondo. Misurare l'efficacia non è un progetto secondario: è il modo in cui rendiamo il SOC a prova di futuro.
Non si tratta di avere più dati, ma dati migliori.
Siamo sinceri: una GenAI senza dati validi è come assumere Sherlock Holmes e bendargli gli occhi.
In Vectra AI, i dati sono il fattore di differenziazione. Due cose li rendono speciali:
- Rilevamenti basati sull'intelligenza artificiale: sviluppati sulla base di anni di ricerca sui comportamenti degli aggressori, non sulle anomalie. Sono progettati per essere robusti, il che significa che rimangono efficaci anche quando gli aggressori cambiano strumenti. Ogni rilevamento si concentra sull'intento e sul comportamento piuttosto che su indicatori statici, dando ai team SOC la certezza che ciò che vedono è reale e rilevante.
- Metadati di rete arricchiti: telemetria ad alto contesto che abbraccia ambienti ibridi, strutturata e correlata in modo da essere leggibile da macchine e immediatamente utilizzabile.
Questo è il tipo di dati che GenAI può effettivamente utilizzare. Inseriscili in un LLM e inizierà a ragionare come un analista esperto. Inserisci i log grezzi e otterrai un'allucinazione molto attendibile sul DNS.
Ma allora, come si valuta un analista AI?
A quanto pare, non basta semplicemente chiedergli di "trovare i cattivi più velocemente".
È necessario misurare il suo modo di ragionare. Quando si ha a che fare con un agente AI con MCP, ci sono principalmente 3 cose su cui è possibile influire:
- Il modello (GPT-5, Claude, Deepseek, ecc.)
- Il prompt (come gli dici di agire: tono, struttura, obiettivi)
- L'MCP stesso (come si collega al tuo stack di rilevamento)
Ognuno di questi fattori può influire sulle prestazioni.
Modifica leggermente il prompt e improvvisamente il tuo analista AI "sicuro di sé" dimentica come si scrive "PowerShell".
Cambia il modello e la latenza raddoppia.
Modifica l'integrazione MCP e metà del tuo contesto scomparirà.
Ecco perché abbiamo creato un banco di prova ripetibile: valutazione automatizzata, scenari SOC reali e un pizzico di brutale onestà.
Il banco di prova (ovvero "l'abbiamo provato davvero")
Per la prima esecuzione, abbiamo volutamente mantenuto le cose semplici: compiti di livello 1, ragionamenti semplici (massimo due passaggi), nessuna coreografia multi-agente elaborata.
La pila aveva questo aspetto:
- n8n per la prototipazione rapida e l'automazione
- Server Vectra QUX MCP per accedere ai dati e gestire la piattaforma.
- Un prompt SOC minimale (in sostanza: "Sei un analista AI. Dai una mano. Se non sai qualcosa, dillo.")
- Valutazione basata su un LLM che confronta le risposte previste con quelle effettive
Ma non si è trattato di un esperimento giocoso. Abbiamo testato 28 attività SOC reali, quelle che gli analisti affrontano ogni giorno. Ad esempio:
- Elenco degli host in stato elevato o critico
- Rilevamento delle operazioni di pull per endpoint specifici (piper-desktop, deacon-desktop, ecc.)
- Verifica dei rilevamenti di comando e controllo associati a IP o domini
- Rilevamento di esfiltrazione superiore a 1 GB
- Contrassegnare ed eliminare gli artefatti host
- Ricerca di conti nei quadranti di rischio "elevato" o "critico"
- Ricerca di account "Admin" coinvolti nelle operazioni EntraID
- Richiesta di rilevamenti con impronte digitali JA3 specifiche
- Assegnazione degli analisti agli host o ai rilevamenti
In sostanza, tutto ciò che un analista SOC di livello 1 o 2 dovrebbe affrontare in un frenetico martedì mattina.
Ogni esecuzione è stata valutata in base alla correttezza, alla velocità, all'uso dei token e all'attività degli strumenti, il tutto misurato su una scala da 1 a 5.
Cosa rende un agente GenAI efficace?
Valutare la GenAI all'interno di un SOC non significa stabilire quale modello sia più intelligente, ma piuttosto quanto sia efficiente nel pensare, agire e apprendere. Un buon agente AI si comporta come un analista brillante: non solo ottiene la risposta giusta, ma la ottiene in modo efficiente. Ecco cosa cercare:
- Uso efficiente dei token. Meno parole servono per ragionare, meglio è. I modelli prolissi sprecano risorse di calcolo e spazio contestuale.
- Chiamate intelligenti degli strumenti. Quando un modello continua a chiamare lo stesso strumento più volte, sta sostanzialmente dicendo "fammi riprovare". I migliori capiscono quando e come utilizzare uno strumento: minimo tentativo ed errore, massima precisione.
- Velocità senza approssimazioni. La rapidità è positiva, ma solo se accompagnata dalla precisione. Il modello ideale bilancia la reattività con la profondità di ragionamento.
In breve: il tuo miglior analista AI non si limita a parlare, ma pensa in modo efficiente.
Ecco cosa abbiamo scoperto:

Punti salienti e consigli pratici
- GPT-5 vince in termini di accuratezza e profondità di ragionamento, ma è lento e costoso. Da utilizzare quando la precisione è più importante della velocità.
- Claude Sonnet 4.5 offre il miglior equilibrio complessivo: precisione, velocità ed efficienza. Ottimo per SOC di produzione.
- Claude Haiku 4.5 è perfetto per una valutazione rapida: veloce, economico e "sufficientemente valido" per le decisioni di prima linea.
- Deepseek 3.1 è il campione del valore: prestazioni impressionanti a un costo ridotto.
- Grok Code Fast 1 è pensato per flussi di lavoro che richiedono un uso intensivo di strumenti (automazione, arricchimento, ecc.), ma fai attenzione al costo dei token.
- GPT-4.1... diciamo solo che non è stato invitato a tornare per un altro turno.
E poiché ogni buon articolo ha bisogno di grafici, eccone alcuni:
Confronto dei punteggi di correttezza

GPT-5 è tecnicamente il vincitore con 4,32/5, ma onestamente? Claude Sonnet 4,5 e Deepseek 3,1 sono praticamente alla pari con 4,11 e probabilmente non noterete la differenza. Il vero colpo di scena? GPT 4,1 fa un vero e proprio flop con 2,61/5. Cavolo. Non usatelo per questioni di sicurezza.
Tempo di esecuzione
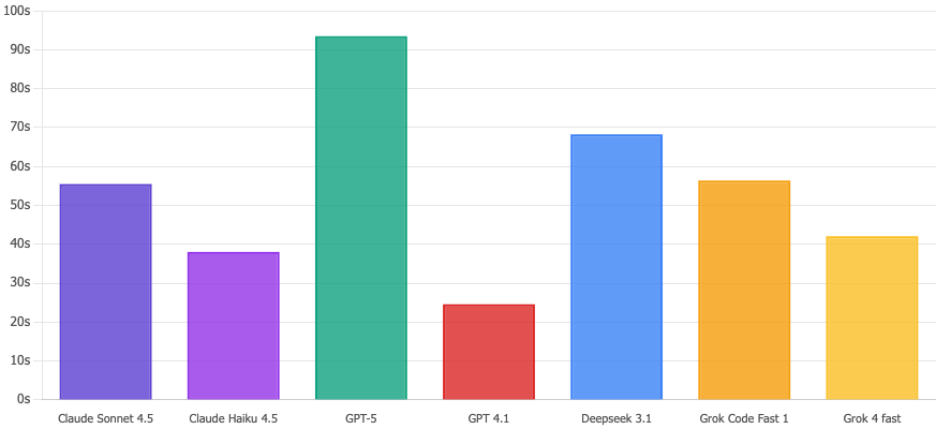
Claude Haiku 4.5 è un e che elabora queste query in 38 secondi. Nel frattempo, GPT-5 impiega ben 93 secondi, ovvero 2,5 volte di più. Quando si verifica un potenziale incidente di sicurezza, quei secondi in più sembrano un'eternità. Haiku porta a termine il lavoro.
Matrice della proposta di valore
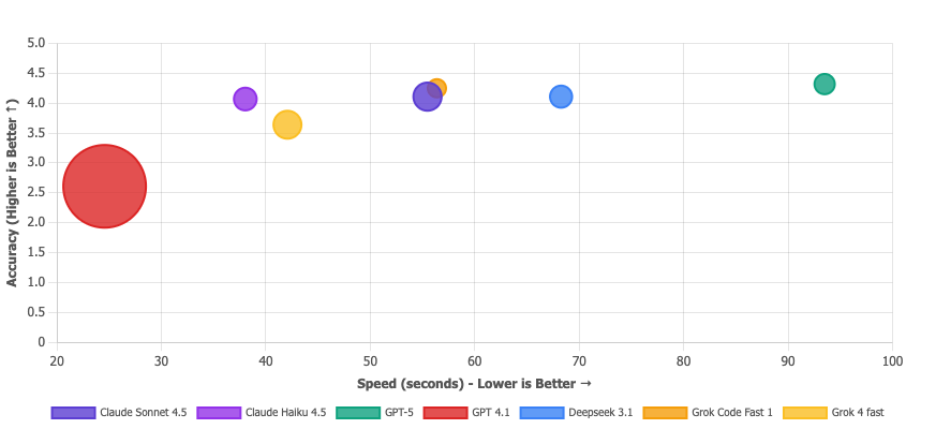
Bolla più grande = meno token utilizzati. La bolla di GPT 4.1 è enorme, ma non è un vanto: è come dire "Ho finito il test in un attimo" quando invece l'hai fallito. Economico e sbagliato non è una proposta di valore, è semplicemente... sbagliato. I modelli che realmente desideri sono nell'angolo in alto a destra: Deepseek 3.1 (efficiente E accurato), Claude Sonnet 4.5 (un mostro equilibrato) e Grok Code Fast (solido a tutto tondo). La microbolla di GPT-5 conferma che è l'opzione costosa.
Allora, cosa abbiamo imparato?
- La precisione non è tutto. Un modello leggermente più preciso ma che richiede il doppio del tempo e consuma cinque volte più token potrebbe non essere l'opzione migliore. In un SOC, l'efficienza e la scalabilità fanno parte della precisione.
- L'uso degli strumenti è una finestra sul ragionamento. "Se un LLM ha bisogno di dieci chiamate allo strumento per rispondere a una semplice domanda, non è accurato, è perso. I modelli più performanti non solo hanno fornito la risposta corretta, ma ci sono arrivati in modo efficiente, utilizzando una o due query intelligenti attraverso l'MCP. L'uso degli strumenti non riguarda la quantità, ma la rapidità con cui il modello individua il percorso corretto. Non è sempre colpa dell'LLM. Un buon server MCP è essenziale per una chiamata ottimale degli strumenti. Ma rimandiamo la valutazione dell'MCP a un momento successivo.
- Il design dei prompt è sottovalutato. La più piccola modifica nella formulazione può influire notevolmente sui tassi di accuratezza o di allucinazione. Abbiamo volutamente mantenuto il prompt minimale, come base di riferimento per future modifiche, ma è chiaro che piccole scelte di design hanno grandi effetti.
Conclusione (e un po' di realismo)
Quindi, il punto è questo: non si tratta davvero di quale modello vincerà un concorso di bellezza. Certo, GPT-5 potrebbe superare Claude in un parametro o nell'altro, ma non è questo il punto.
La vera lezione è che valutare il proprio agente AI non è facoltativo.
Se avete intenzione di affidarvi alla GenAI all'interno del vostro SOC — per smistare gli avvisi, riassumere gli incidenti o persino richiamare azioni di contenimento — allora dovete sapere come si comporta, dove fallisce e come si evolve nel tempo.
L'intelligenza artificiale senza valutazione è solo automazione senza responsabilità.
Altrettanto importante: i tuoi strumenti di sicurezza devono parlare LLM.
Ciò significa dati strutturati, API pulite e contesti leggibili dalle macchine, non bloccati in dashboard o silos dei fornitori. Anche il modello più avanzato al mondo non è in grado di ragionare se alimentato con dati telemetrici incompleti.
Ecco perché noi di Vectra AI ci impegniamo al massimo per garantire che la nostra piattaforma e il nostro server MCP siano progettati per supportare l'LLM. I segnali che produciamo non sono destinati solo agli esseri umani, ma sono pensati per essere utilizzati dalle macchine, dagli agenti di intelligenza artificiale in grado di ragionare, arricchire e agire.
Perché nella prossima ondata di operazioni di sicurezza, non sarà sufficiente utilizzare l'intelligenza artificiale: l'intero ecosistema dovrà essere compatibile con l'intelligenza artificiale.
Il SOC del futuro non è solo basato sull'intelligenza artificiale. È misurato dall'intelligenza artificiale, connesso all'intelligenza artificiale e pronto per l'intelligenza artificiale.